顾名思义,机器学习的目的就是让机器具有类似于人类的学习、认识、理解事物的能力。试想一下,如果计算机能够对大量的癌症治疗记录进行归纳和总结,并能够给医生提出适当的建议和意见,那对病人的康复来说,是多么的重要。除了医疗领域,金融股票、设备维护、自动驾驶、航空航天等领域也对机器学习表现出了越来越多的关注。
一个典型的机器学习系统可以用下面的图来表示:
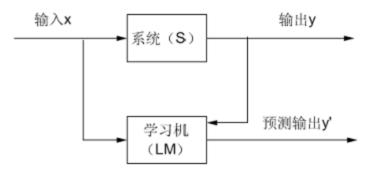
其中,系统S是我们研究的对象,它在给定一个输入x的情况下,得到一定的输出y,LM是我们所求的学习机,其输出为y'。机器学习的目的是根据给定的训练样本求取系统输入输出之间的依赖关系的估计,使它能够对未知的输出做出尽可能准确的预测。
机器学习问题可以形式化地表示为:已知变量y与输入x之间存在一定的未知依赖关系,即存在一个未知的映射F(x,y),(x和y之间的确定性关系可以看做是一个特例),机器学习就是根据n个独立同分布的观测样本
在一组函数 中求一个最优的函数
中求一个最优的函数 ,使预测的期望风险
,使预测的期望风险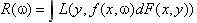 最小。其中
最小。其中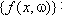 ,被称为预测函数集,
,被称为预测函数集,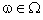 为函数的广义参数,故
为函数的广义参数,故 可以表示任何函数集;
可以表示任何函数集;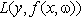 为由于
为由于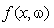 对y进行预测而造成的损失。不同类型的学习问题有不同形式的损失函数。预测函数也叫做学习函数、学习模型或学习机器。
对y进行预测而造成的损失。不同类型的学习问题有不同形式的损失函数。预测函数也叫做学习函数、学习模型或学习机器。
通常来说,为了能够得到一个完善的机器学习系统,需要依次进行以下的步骤:
(一)选择训练经验:给学习机器提供的训练经验的选择对于系统的成败有着重要的影响。一般来讲,训练经验应该能够直接或者间接的对系统的决策做出一定的反馈,训练经验应该能够在很大程度上控制训练样例的序列;此外,训练经验还应该可以进可能的对训练样本和测试样本的空间概率分布做出很好的估计。
(二)选择目标函数:在给定训练样本和训练经验之后,机器学习问题就简化为一个寻找理想目标函数F(x)的问题。
(三)选择目标函数的表示形式:事实上,通过对样本的学习和训练来得到理想的目标函数F(x)是非常困难的,通常我们都希望能够得到一个近似的目标函数来尽量近似逼近理想的目标函数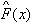 。这里的近似逼近,可以采用二次多项式函数、神经网络等方法来实现。
。这里的近似逼近,可以采用二次多项式函数、神经网络等方法来实现。
(四)选择函数逼近算法:为了得到近似目标函数,我们根据选择的初始近似目标函数对训练样本的输入进行估计,从而得到训练样本的估计输出,之后,利用估计输出与实际输出之间的误差来进行反馈,通常是进行权值调整。接着,对系统的输入进行重新估计,得到新的输出估计值,重新计算估计值与实际值之间的误差,再次对系统进行反馈,调整权重,依次重复执行直到所有训练样本的总误差小于设定的阈值或者训练次数大于设定的次数。
分享到:




相关推荐
《李宏毅深度学习笔记》
① 先假设 只有 未知参数 W ② 假设有 两个 参数 , 170 ⑥ ① ② ④
《人工智能应用基础》相关知识基础机器学习基本概念(1) 模型从数据中学得模型的过程称为“学习”或“训练”,这个过程通过执行某个学习算法来完成。训练过程中使用的数据称为“训练数据”(training data),其中每个...
机器学习--神经网络机器学习--神经网络机器学习--神经网络机器学习--神经网络
华中科技大学 源码和实验报告 基于《MovieLens电影评分数据集》使用各种机器学习方法《预测电影评分》,找出最佳的机器学习算法.zip
1.2.1基本概念 训练集 测试集 特征值 监督学习 非监督学习 半监督学习 分类 回归 1.2.2例子1 针对例子1,我们可以把100天的数据(包括每天的温度X1,天气X2,风力X3,水温X4,湿度X5,预报X6和小明每天是否享受...
介绍了概念学习的基本方法,对归纳学习进行了阐述
对机器学习基本概念以及数学定义 基本性质及其物理意义 具体算法应用(详细举例讲解) 该算法与其他类似算法的分析比较 可能的发展方向进行介绍,可作为机器学习快速入门学习,已经框架介绍资料 附参考文献
个人对机器学习基本概念的理解,属于思维导图类型,如果好的话,后期可能会更新。毕竟,一见无始便有坑,后续只能把坑盛。xmind
本书为读者提供机器学习和R语言的坚实算法基础和业务基础,内容包括机器学习基本概念、线性回归、逻辑回归和判别分析、线性模型的高级选择特性、K最近邻和支持向量机等,力图平衡实践中的技术和理论两方面
首先,介绍了量子计算和机器学习的基本概念;其次,从四个方面分别介绍了量子机器学习,分别是量子无监督聚类算法、量子有监督分类算法、量子降维算法、量子深度学习;同时,对比分析量子机器学习算法与传统机器学习算法的...
通过网络爬虫收集的最新数据挖掘算法资料,绝对干货!
有公式写不了博客,只能上传了,为什么没有0分资源。...机器学习,深度学习的一些基本概念,找工作整理得。 有公式写不了博客,只能上传了,为什么没有0分资源。 机器学习,深度学习的一些基本概念,找工作整理得。
包括人工智能、概率统计、信息论、神经生物学等学科的发展为机器学习提供了丰富的素材
关于机器学习的意义,基本的概念,基本的认知与发展趋势,统计机器学习的基本方法, 典型机器学习开发包。
机器学习_核函数基本概念.doc
想入门机器学习领域或深度学习领域的不可或缺之物
清华大学-学堂在线 大数据机器学习课件笔记系列:概述、机器学习的基本概念、模型性能评估、感知机、聚类、贝叶斯分类器及图模型、决策树和随机森林、逻辑斯谛回归与最大熵模型、支持向量机 SVM、核函数与非线性 SVM...